The missing JOIN

I was recently inspired watching a recording of Lloyd Tabb presenting Malloy, a project I’ve been following for a while, and even contributed (the tiniest feature) to. I’ve embedded the video below.
A point he makes that resonated with me is how data isn’t rectangular, and I’ve long appreciated tools like BigQuery and how they support repeated and nested data structures. When working at Spotify, I was even on stage at our internal Analytics conference talking about this topic.
If you watched the video above, you saw the classical example of a join with a non-unique key causing repetition of data, and hence erroneous sums. I’d argue this way of joining tables is a legacy from the time when tables had to be rectangular (no nested/repeated/array field types). I even included a suggested addition to SQL in a previous post that I called “JOIN TO ARRAY” . I’d like to elaborate a bit more on that feature.
.. because today, we have array field types, and an arguably more intuitive JOIN strategy would be to have one relation join into an array in the other relation — hence forcing the query author to explicitly handle the possible duplication of information.
I figure here is where an example would be nice!
Let’s say you have the tables below (yeah, I “stole” them from the video):
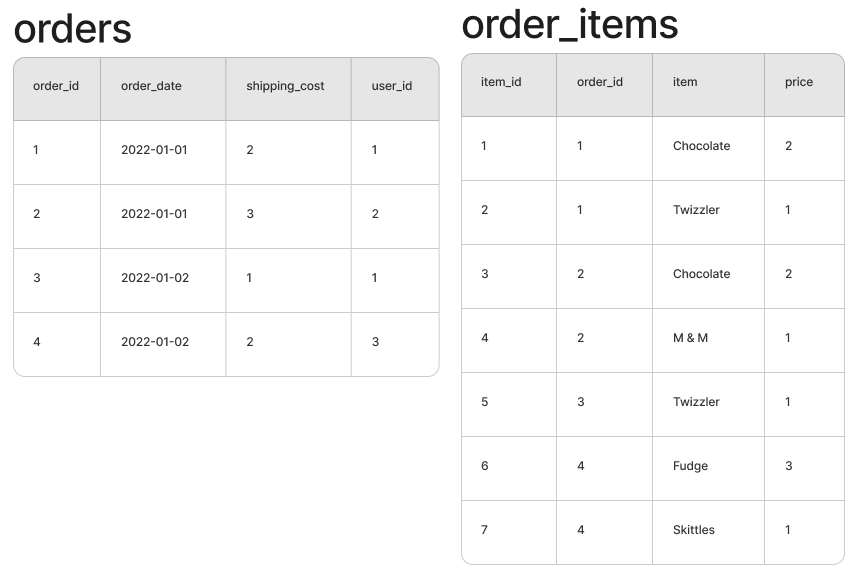
… and you join the two on the order_id column.
In other words
SELECT
*
FROM
orders
LEFT OUTER JOIN
order_items
USING(order_id)Your result will look like below, with the all so familiar repetition of shipping cost, breaking any calls of SUM on that column.
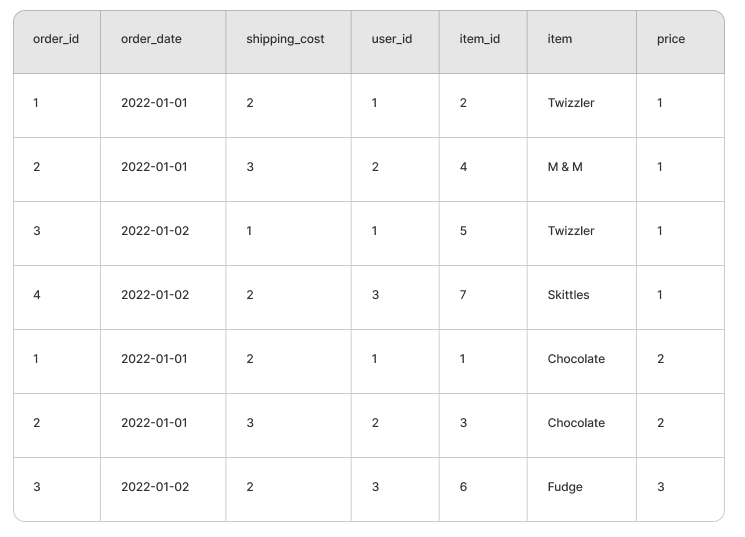
… my proposed syntax would do some of what Malloy is achieving (and possibly making Malloy’s query generation more straightforward) by not expanding the rows from orders, but instead putting the matched order_items in an array.
SELECT
*
FROM
order_items
JOIN INTO -- naming is ofc TBD, what about "NEST INTO"?
orders
USING(order_id)Syntax can of course be debated, and showing a table with repeated fields in an image is hard, anywho, bear with me as I try to illustrate the intended results:
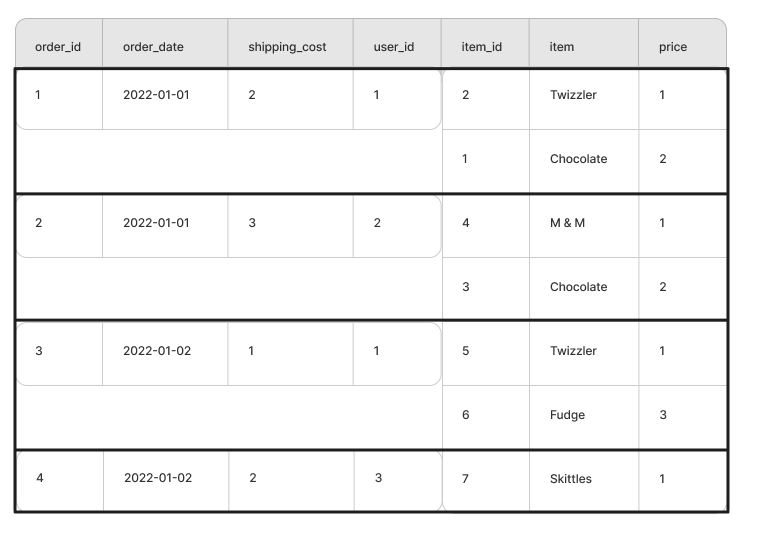
As you see, there are still only four records, where each record contains an array of items from the join operation. (When working with data like this, I prefer the term “record” over “row” when referring to the data)
It is now up to the query author to decide how to aggregate this. In BigQuery, this could look like:
SELECT
SUM(shipping_cost) AS total_shipping,
SUM((SELECT SUM(price) FROM order_items)) AS total_price
FROM
order_items
JOIN INTO
orders
USING(order_id)What this pattern also does, is to greatly simplify data denormalisation, which is still a very hot pattern to create datasets that enable performant analytics queries. In essence, instead of having to do a join in every query, you can store the joined data, without having to take care of any deduplication or similar.
Also, I don’t think it would be too hard to implement. The above query example, could be re-written in BigQuery SQL as:
SELECT
SUM(shipping_cost) AS total_shipping,
SUM((SELECT SUM(price) FROM order_items)) AS total_price
FROM
(
SELECT
orders_id,
ANY_VALUE(order_date) AS order_date,
ANY_VALUE(shipping_cost) AS shipping_cost,
ANY_VALUE(user_id) AS user_id,
ARRAY_AGG(order_item) AS order_items
FROM
orders
LEFT OUTER JOIN
order_items AS order_item
USING(order_id)
GROUP BY
order_id
)Note how the inner query above is a quite powerful denormalisation pattern, i.e. the result of that query could be stored in a new table for analysis … and while the above re-write means this is likely quite easy to implement, I am also certain that the under-the-hood query rewriter and optimisations will be able to do this even more efficiently with some tweaks.
Lastly, that third row in the last example, where I throw a query at a nested record, if the above become common practice, we may want a shorthand for that too.
And that’s all I had to say today :)